
Build and Test Athena Queries Locally Without AWS Costs!
- Mohamed Imam
- 0 Comments
Sometimes we need to test AWS Athena queries, but doing so directly can lead to unexpected costs if something goes wrong. To avoid this, you can test Athena-like queries locally using Trino. In this guide, we’ll install Trino on your laptop and run a simple query against a Parquet file.
Installing Trino:
I’m using Ubuntu 24.04 LTS. To get started, we’ll need to install Python and Java as prerequisites.
apt install python -y
sudo apt install openjdk-21-jdk -yFor confirmation:
python --version
java --version
Download Trino (Earlier known as Presto)
wget https://repo1.maven.org/maven2/io/trino/trino-server/438/trino-server-438.tar.gzExtract the downloaded tar archive
tar -xvzf trino-server-438.tar.gzMove it to the /opt directory (or any other location you prefer).
sudo mv trino-server-438 /opt/trinoCreate configuration directory for Trino:
sudo mkdir -p /opt/trino/etc/catalogThen create a config file:
sudo vim /opt/trino/etc/config.propertiesUse the following content (feel free to modify the options, such as changing the port number, to suit your setup).
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8090
query.max-memory=5GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://localhost:8090Create a jvm.config
sudo vim /opt/trino/etc/jvm.configWith the following content:
-server
-Xmx16G
-XX:+UseG1GC
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryErrorCreate node.properties
sudo vim /opt/trino/etc/node.propertieswith the following content:
node.environment=production
node.id=trino-coordinator
node.data-dir=/opt/trino/dataFor our demo, we will use Parquet files locally on same system where we are running Trino.
So we will create a hive catalogue like this:
sudo vim /opt/trino/etc/catalog/hive.propertiesWith the following content:
connector.name=hive
hive.metastore=file
hive.metastore.catalog.dir=file:///opt/trino/data/hive/warehouse
hive.metastore.user=trinoThis configuration tells Trino to use /opt/trino/data/hive/warehouse as the data warehouse directory with a file-based metastore. We’ll place our Parquet file in this directory.
Now, we need to start the Trino server and connect to it. First, navigate to /opt/trino, then run the following command:
bin/launcher start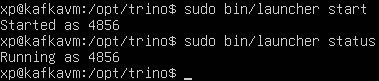
Now we need to install trino-cli ( Trino CLI provides a terminal-based, interactive shell for running queries)
wget https://repo1.maven.org/maven2/io/trino/trino-cli/438/trino-cli-438-executable.jar -O trino
chmod +x trinoTo connect to Trino running on localhost, use the following command (we’re using port 8090, as specified earlier in the configuration file):
./trino --server localhost:8090 --catalog hiveI created a folder at:/opt/trino/data/hive/warehouse/
sudo mkdir /opt/trino/data/hive/warehouse/my_table/Then, I copied my Parquet file into that folder:

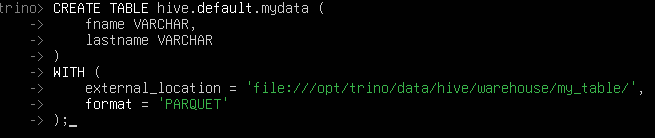
Next, we need to create a Hive table pointing to the folder containing our Parquet file. Be sure to define the column names and data types exactly as they appear in the Parquet file.
CREATE TABLE hive.default.mydata (
fname VARCHAR,
lastname VARCHAR
)
WITH (
format = 'PARQUET',
external_location = 'file:///opt/trino/data/hive/warehouse/my_table/'
);
Finally, we can run queries against our Parquet file.
SELECT * FROM hive.default.mydata WHERE fname = 'Karim';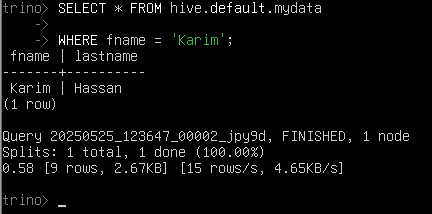
I hope you find this helpful and that it allows you to test Athena queries freely without worry.